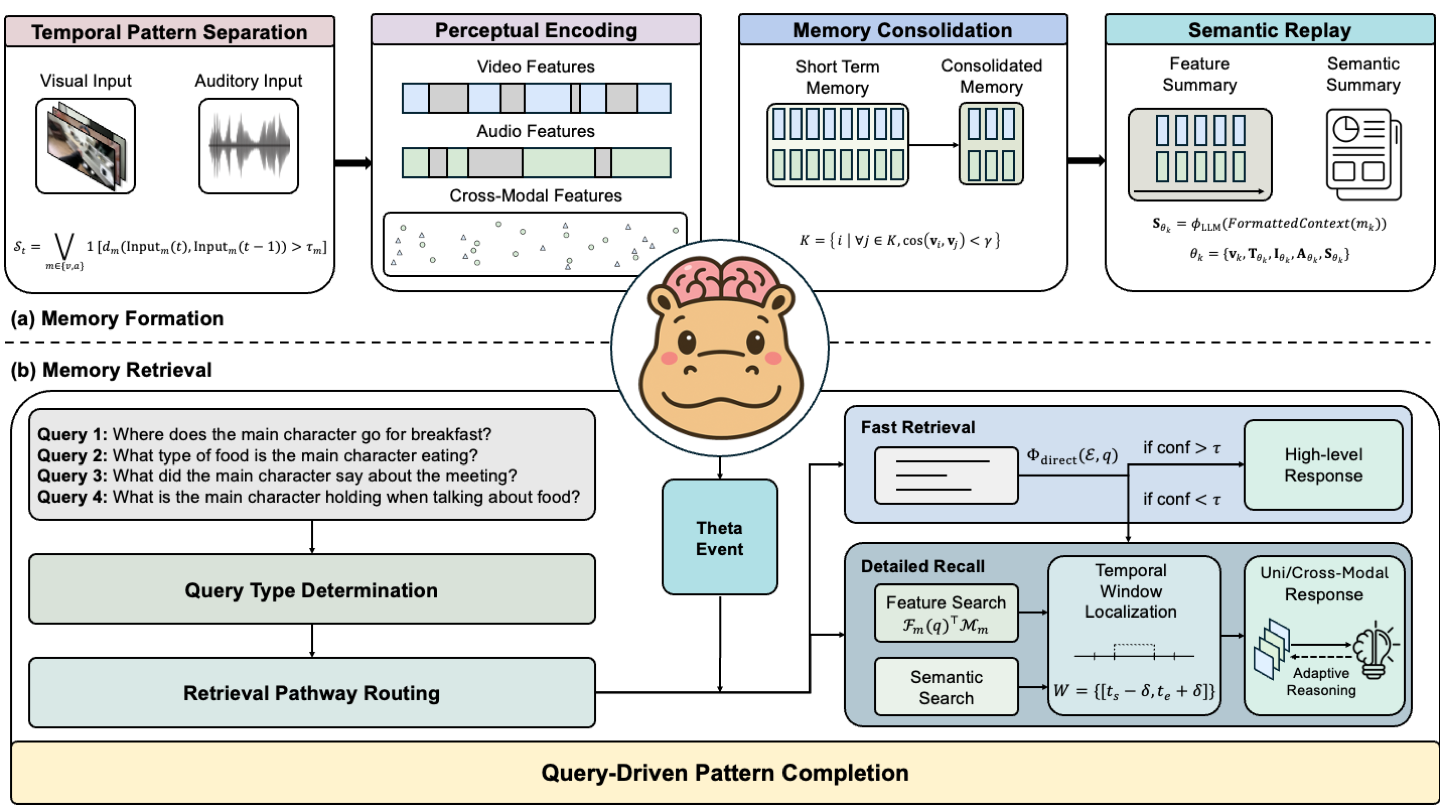
Method
HippoMM introduces a novel architecture inspired by the human hippocampus to handle long audiovisual events. The system consists of three main components:
- Pattern Separation and Completion: Specialized neural networks process continuous audiovisual streams, separating distinct events while maintaining temporal coherence.
- Memory Consolidation: A hierarchical memory system that transforms raw perceptual inputs into semantic representations through progressive abstraction.
- Cross-modal Retrieval: Novel attention mechanisms enable efficient querying across modalities while maintaining temporal context.
The architecture dynamically segments input streams using adaptive temporal windows and implements a dual-process encoding strategy that balances detailed recall with efficient retrieval.